近日,來自英國杜倫大學(xué)等3所高校學(xué)者發(fā)表的一篇論文指出,最先進(jìn)的人工智能模型,僅憑筆記本電腦的按鍵聲音,就可以還原用戶輸入的密碼和敏感信息。

《基于深度學(xué)習(xí)的鍵盤聲學(xué)側(cè)信道攻擊實用技術(shù)》
在這項研究中,研究人員用深度學(xué)習(xí)的方法首次提出了一個完全自動化的鍵盤聲學(xué)側(cè)信道攻擊流程,包括按鍵分割、通過mel頻譜圖進(jìn)行特征提取、使用CoAtNet模型進(jìn)行分類幾個大的部分。
過去研究側(cè)信道攻擊
側(cè)信道攻擊,也叫邊信道攻擊,其核心就是通過加密軟件或硬件在運行時產(chǎn)生的各種泄露信息來間接獲取密文信息。
過去,人們在研究聲學(xué)側(cè)信道攻擊時廣泛使用的是機器學(xué)習(xí)方法,常見的一種方法是利用隱馬爾可夫模型(HMM),即一種在文本語料庫中訓(xùn)練出來的模型,主要用于預(yù)測序列中最有可能出現(xiàn)的單詞或字符。
比如,當(dāng)分類器中輸出“Hwllo”時,HMM可用來推斷單詞中的“w”實際上是被錯誤分類的“e”。該方法盡管在很多文本處理類的場景中比較有效,但一個最大的缺點就是輸出了很強的獨立性假設(shè),不能考慮上下文的特征,使得對真實情況的建模能力變?nèi)趿耍绕湓诿媾R無序的密碼場景中比較受限,這也可能是HMM近來不受歡迎的原因之一。
來看看該研究的具體過程:
第一步,收集數(shù)據(jù)
在兩組不同模式(手機和Zoom)的實驗中,研究人員通過按壓筆記本電腦的36個按鍵(0-9、a-z)來進(jìn)行;在用不同角度和力度對每個按鍵分別按壓25次后,一個記錄聲音的數(shù)據(jù)文件就產(chǎn)生了。
ps:在本次實驗中,研究人員選取了一臺配備16GB內(nèi)存和蘋果M1 Pro處理器的MacBook Pro16英寸(2021年)筆記本電腦作為攻擊對象。該電腦的鍵盤開關(guān)設(shè)計與過去兩年的機型及未來可能推出的機型完全相同,且同期可用的型號很少,鍵盤也基本相同。

△ 手機距離目標(biāo)17cm
第二步,擊鍵隔離
所有按鍵數(shù)據(jù)都被記錄后,研究人員就用當(dāng)前信號分析的一種最基本方法——快速傅里葉變換(FFT),對按鍵聲音進(jìn)行了提取,并對不同頻率的系數(shù)求和以獲取能量;之后再定義一個能量閾值,當(dāng)信號超過閾值時則標(biāo)記為按鍵。
值得注意的是,由于Zoom在錄音過程中存在噪聲抑制,很難設(shè)定能量閾值,研究人員采取了一種不斷調(diào)整閾值的循環(huán)方法來解決,直到找到正確的按鍵次數(shù)。
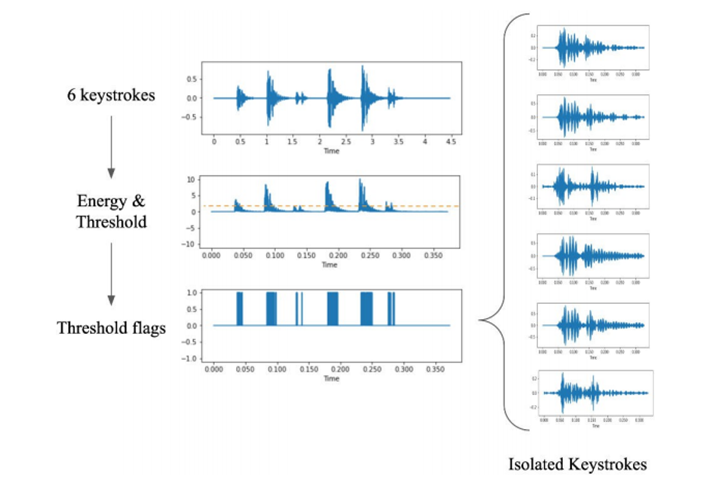
第三步,特征提取
這一步,研究人員采用了梅爾頻譜圖方法將聲音特征提取出來,讓每個按鍵的差異可識別。
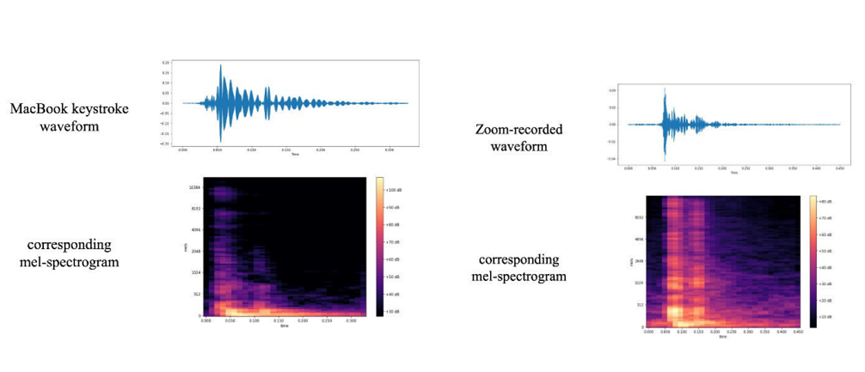
△左圖為手機錄音的波形圖和相應(yīng)的mel頻譜圖,右圖為Zoom錄音。
第四步,數(shù)據(jù)增強
為了促進(jìn)模型的泛化,即提高機器學(xué)習(xí)模型對新的、未見過的數(shù)據(jù)的適應(yīng)能力,避免過度擬合訓(xùn)練數(shù)據(jù),研究人員同時使用了屏蔽法進(jìn)行數(shù)據(jù)增強,即通過隨機抽取時間軸和頻率軸的部分?jǐn)?shù)據(jù),并將這些范圍內(nèi)的所有值設(shè)置為頻譜圖的平均值,從而“屏蔽”部分圖像。
第五步,建立模型
這也是本次實驗中最為關(guān)鍵的一步。
研究人員將mel頻譜圖作為聲音的視覺表示,以圖像的形式輸入到CoAtNet(一個圖形算法)中。CoAtNet包含卷積層(特征提取)和自注意力層(特征識別),可以高效學(xué)習(xí)特征并建模特征之間的全局關(guān)系。
并在CoAtNet的基礎(chǔ)上添加了平均池化層和全連接層,以得到最終的按鍵分類結(jié)果。
此外,研究人員還使用了交叉熵?fù)p失函數(shù)和Adam優(yōu)化器訓(xùn)練模型,訓(xùn)練過程中,每5個epoch測試一次驗證集精度。通過調(diào)節(jié)學(xué)習(xí)率、epoch數(shù)量等超參數(shù),解決了模型精度突降的問題。
這樣一來,CoAtNet的輸出結(jié)果就可以被縮減為與每個鍵相關(guān)的百分比。
總結(jié)來說,就是把前面收集到的鍵盤敲擊的聲音文件,進(jìn)行頻譜圖像識別、提取、加強后,放到這個CoAtNet中,建立數(shù)據(jù)模型進(jìn)行分析,比如敲擊字母F的頻譜圖像和字母D的頻譜圖像,具有不同的敲擊特征,那么模型就會分別對這兩個頻譜圖像進(jìn)行分析,從而分辨出哪個是F,哪個是D。
手機和Zoom兩種錄音方式的結(jié)果僅差2%,也側(cè)面說明了錄音方式的改變不會對準(zhǔn)確率產(chǎn)生顯著影響。
此外,值得一提的是,研究人員還發(fā)現(xiàn)大多數(shù)誤分類都是相鄰按鍵,錯誤具有一定規(guī)律性。
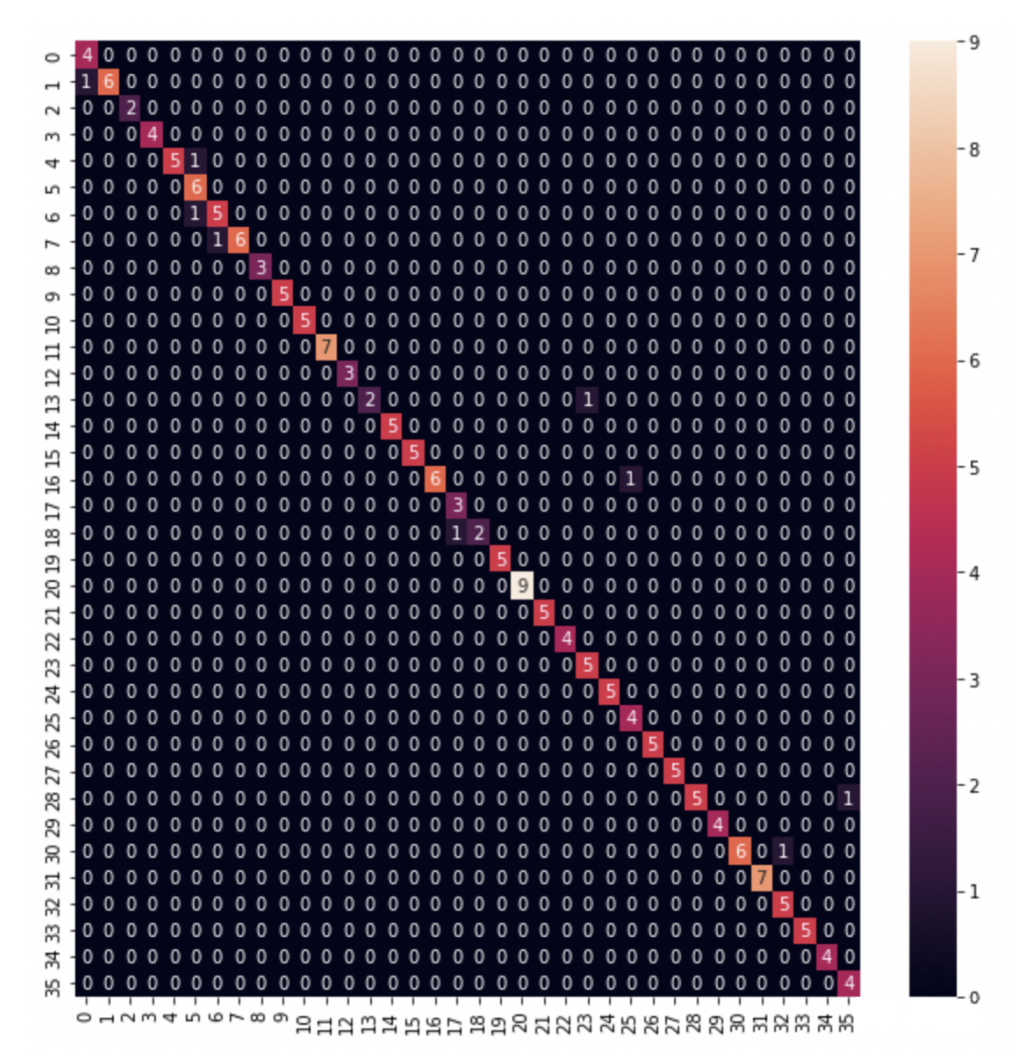
△ 手機錄制的MacBook按鍵分類器的混淆矩陣
最終,研究人員的實驗結(jié)果顯示:通過手機錄音的按鍵分類準(zhǔn)確率達(dá)到了95%,而在Zoom錄制的數(shù)據(jù)集中,分類準(zhǔn)確率則達(dá)到了93%。簡單來說,一個8位數(shù)的密碼可能其中7個都可以被正確識別,而剩下的那一個被錯誤識別的也被證明往往集中在正確按鍵周圍的位置!
既然如此,我們還有應(yīng)對的辦法嗎?
答案是肯定的。比如硬件層面,使用能減少向外部傳遞信號的部件或者對信號制造干擾;軟件層面,升級安全防御軟件或定期更新;還有用戶層面,盡量使用復(fù)雜組合的密碼并且經(jīng)常更換……
資料來源 | 科學(xué)大院-江邊、知乎-Blue





 粵公網(wǎng)安備 44030502007885號
粵公網(wǎng)安備 44030502007885號